주기억장치는 ‘워드(word)’ 단위로 데이터가 저장되고 캐시 기억장치는 ‘블록(block)’ 단위로 데이터가 저장된다. 이때 워드는 비트(bit)*의 집합이고 블록은 연속된 워드 여러 개의 묶음을 말한다. 주기억장치의 데이터가 캐시 기억장치에 저장되는 장소를 ‘라인(line)’이라고 한다. 캐시 기억장치는 일반적으로 하나의 라인에 하나의 블록이 들어갈 수 있도록 설계되어 있기 때문에 주기억장치에서 캐시 기억장치로 데이터를 전송할 때에는 블록 단위로 데이터를 전송한다. 캐시 기억장치의 용량은 주기억장치보다 훨씬 작기 때문에 주기억장치의 블록 중에서 일부만 캐시 기억장치에 저장될 수 있다. 그러므로 캐싱을 위해서는 주기억장치의 여러 블록이 캐시 기억장치의 하나의 라인을 공유하여 사용해야 한다.
예를 들어 어떤 컴퓨터의 주기억장치의 데이터 용량을 워드 2n개, 캐시 기억장치의 데이터 용량을 워드 M개라고 가정해 보자. 이때 주기억장치의 블록 한 개가 K개의 워드로 이루어져 있다고 하면 이 주기억장치의 총 블록 개수는 2n/K개가 되며 각 워드는 n비트의 주소로 지정된다. 그리고 캐시 기억장치의 각 라인은 K개의 워드로 채워지므로 캐시 기억장치에는 총 M/K개의 라인이 만들어진다.
*비트: 컴퓨터에서 정보를 나타내는 가장 기본적인 단위. 2진수의 0 또는 1이 하나의 비트.
<2020학년도 9월 교육청 전국연합평가>
‘워드(word)’ 단위로…‘블록(block)’ 단위로…워드는 비트(bit)의 집합…블록은…워드…의 묶음
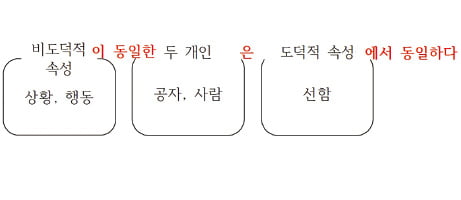
‘A 단위로 B’라는 어구에서 A는 B라는 개념을 구분하는 말이다. 사람들을 동민, 구민, 시민 등으로 구분하듯이 ‘워드’ ‘블록’도 ‘데이터’를 구분하는 개념인 것이다. ‘비트’도 마찬가지다. 낱말 풀이에서 보다시피 비트는 정보를 나타내는 기본 단위인데, ‘정보’를 우리는 데이터라고 하므로, 비트도 데이터를 구분하는 개념이다.
그런데 ‘A는 B의 집합’ ‘A는 B의 묶음’과 같은 어구는 개념들의 상하 관계를 고려하며 이해해야 한다. ‘동민<구민<시민’이듯이, ‘비트<워드’ ‘워드<블록’이라는 계층적 상하 관계가 성립한다. 특히 워드의 위상에 주목해보자. 워드는 비트의 상위에 있으면서, 블록의 하위에 있다. 개념의 위상은 어디까지나 상대적이다. 예컨대 ‘인간’은 ‘동물’에 포함‘되’면서 동시에 ‘신 샘’을 포함‘한’다. 따라서 워드라는 개념은 블록과 비트 사이의 위상을 가진다.
이를 이해하는 손쉬운 방법이 벤다이어그램[그림1]이나 가지치기 방법[그림2]이다.
많은 학생이 글을 읽을 때 생소한 개념이 나오면 아예 모르거나 정확하게 이해하기 어려워 당황한다. 그런데 그럴 필요가 없을 때도 있다. 여기서는 개념의 의미보다 개념 간 관계를 이해하는 것이 더 중요하다.
하나의 라인에 하나의 블록…캐시 기억장치…은 주기억장치보다…작기…여러 블록이 …하나의 라인을 공유
개수, 용량 등을 비교하면서 읽어야 할 때가 있다. ‘하나의 라인에 하나의 블록이 들어’간다고 했으니, 라인은 그릇에, 블록은 내용물에 비유될 수 있을 것이다. 블록은 데이터를 묶는 단위이다. 따라서 데이터도 내용물에 비유될 수 있다. 그런데 이 부분에서 라인은 블록과 같거나 블록보다 크다는 것을 떠올려야 한다. 내용물의 양이 그릇과 같거나 그릇보다 작으면 담기고, 크면 넘친다.
한편 캐시 기억장치는 주기억장치보다 용량 면에서 작다고 했다. 이상의 내용을 머릿속에 그림을 그려가며 읽을 수 있다.
글을 읽고 그림으로 나타내는 것도 국어 능력의 하나다. 주기억장치를 캐시 기억장치보다 더 크게 그린 것은 용량의 차이를 반영한 것이다. 주기억장치를 4개의 블록으로 나누고 그것을 다시 4개의 데이터로 나눠 그렸다. 캐시 기억장치는 2개의 라인으로 나눴다. 4니, 2니 하는 수는 사례로 주어진 것이니 읽는 사람마다 다른 수를 생각해도 좋다. 다만 여기에서는 용량의 차이, 데이터의 공유 등을 고려할 때 가장 단순하면서도 개념을 모두 포함할 수 있는 적정한 수가 2, 4다. 이런 수를 떠올릴 수 있는 것은 수학적 능력이지만 그것 또한 국어 능력의 하나다.